やる夫で学ぶ機械学習シリーズの第 5 回です。分類問題を解くためのロジスティック回帰を見ていきます。
第 4 回はこちら。やる夫で学ぶ機械学習 - パーセプトロン -
目次はこちら。やる夫で学ぶ機械学習シリーズ
ロジスティック回帰
 やる夫
やる夫
分類問題を解くための素晴らしいアルゴリズムがあると聞きましたお。
 やらない夫
やらない夫
今日は展開が早いな。
やる夫
回りくどいのは終わりだお。
やらない夫
では、今日はロジスティック回帰の話をしていこう。ロジスティック回帰は、パーセプトロンのように基本的には二値分類の分類器を構築するためのものだ。
やる夫
パーセプトロンよりは使い物になるのかお?
やらない夫
もちろんさ。ロジスティック回帰はいろんなところで使われているし、線形分離不可能な問題も解ける。
やる夫
それはナイスだお。
やらない夫
いつものように最初は簡単な具体例を示して概要を見ていこうか。
やる夫
よろしくお願いしますお。
やらない夫
問題設定はパーセプトロンの時と同じものを使おう。つまり、色を暖色か寒色に分類することを考えるんだ。
やる夫
それ、線形分離可能な問題だお?線形分離不可能な問題やらないのかお?
やらない夫
物事には順序ってものがあるだろう。先に基礎からやるんだよ。ロジスティック回帰も、もちろん線形分離可能な問題は解ける。まずそこから入って、その応用で最後に線形分離不可能な問題を見ていこう。
やる夫
基礎力つけるの面倒くさいけど、わかったお…
やらない夫
ロジスティック回帰は分類を確率として考えるんだ。
やる夫
確率?暖色である確率が 80%、寒色である確率が 20%、みたいな話ってことかお?
やらない夫
そうだ、いつもとぼけた顔してる割には冴えてるじゃないか。
やる夫
顔は生まれつきだお。文句いうなお。
やらない夫
暖色、寒色のままでは扱いにくいのはパーセプトロンと同じだから、ここでは暖色を $1$、寒色を $0$ と置くとしよう。
やる夫
あれ、寒色は $-1$ じゃないのかお?
やらない夫
クラス毎の値が異なっていれば別になんでもいいんだが、パーセプトロンの時に暖色が $1$ で寒色が $-1$ にしたのは、そうした方が重みの更新式が簡潔に書けるからだ。
やる夫
なるほど。ロジスティック回帰の場合は暖色を $1$ で寒色を $0$ にした方が、重みの更新式が簡潔に書き表せるってことかお?
やらない夫
そういうことだな。話を進めよう。回帰の時に、未知のデータ $\boldsymbol{x}$ に対応する値を求めるためにこういう関数を定義したのを覚えているか?
$$
f_{\boldsymbol{\theta}}(\boldsymbol{x}) = \boldsymbol{\theta}^{\mathrm{T}}\boldsymbol{x}
$$
やる夫
覚えてるお。学習用データに最も良くフィットするパラメータ $\boldsymbol{\theta}$ を求めた時だお。あの時は最急降下法か確率的勾配降下法を使ってパラメータ $\boldsymbol{\theta}$ の更新式を導出したんだったお。
やらない夫
ロジスティック回帰でも考え方は同じだ。未知のデータがどのクラスに分類されるかを求めたい時に、それを分類してくれるための関数が必要になるな。
やる夫
パーセプトロンでやった時の識別関数 $f_{\boldsymbol{w}}$ みたいなもんかお?
やらない夫
そうだな。今回も回帰の時と同じように $\boldsymbol{\theta}$ を使うことにして、ロジスティック回帰の関数をこのように定義しよう。
$$
f_{\boldsymbol{\theta}}(\boldsymbol{x}) = \frac{1}{1 + \exp(-\boldsymbol{\theta}^{\mathrm{T}}\boldsymbol{x})}
$$
やる夫
急に難易度が上がるのは、このシリーズのセオリーかお。
やらない夫
ぱっと見て難しそうだと感じるのはわかるが、落ち着いて考えるんだ。第一印象で無理かどうかを決めるのは良くないぞ。
やる夫
$\exp(x)$ ってのは $\mathrm{e}^x$ ってことかお?
やらない夫
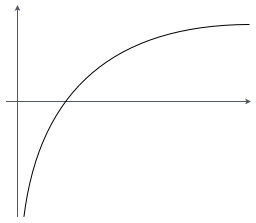
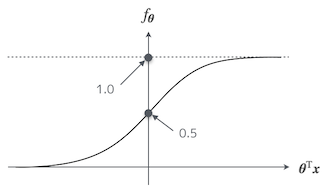
そうだ。この関数は一般的にシグモイド関数と呼ばれるんだが、$\boldsymbol{\theta}^{\mathrm{T}} \boldsymbol{x}$ を横軸、$f_{\boldsymbol{\theta}}$ を縦軸だとすると、グラフの形はこんな風になっている。
やる夫
お、ものすごくなめらかな形をしているお。
やらない夫
特徴としては、$\boldsymbol{\theta}^{\mathrm{T}} \boldsymbol{x} = 0$ の時に $f_{\boldsymbol{\theta}} = 0.5$ になっている。それから、グラフを見ればすぐわかると思うが $0 \le f_{\boldsymbol{\theta}} \le 1$ だ。
やる夫
グラフの形なんか示してどうするんだお。
やらない夫
目に見えるように表現すると見えないモノが見えてくる。今は、分類を確率で考えようとしているんだ。覚えているか?
やる夫
覚えてるお。あ…そうか、シグモイド関数は $0 \le f_{\boldsymbol{\theta}} \le 1$ だから確率として扱える、ってことかお。
やらない夫
その通りだ。ここからは、未知のデータ $\boldsymbol{x}$ が暖色、つまり $y=1$ である確率を $f_{\boldsymbol{\theta}}$ とするんだ。
$$
P(y=1|\boldsymbol{x}) = f_{\boldsymbol{\theta}}(\boldsymbol{x})
$$
やらない夫
具体例を見てみようか。そうだな、$f_{\boldsymbol{\theta}}(\boldsymbol{x})$ を計算すると $0.7$ になったとしよう。これはどういう状態だ?
やる夫
あ、えーっと…$f_{\boldsymbol{\theta}}(\boldsymbol{x}) = 0.7$ ってことは、暖色である確率が 70% ってことかお?逆に寒色である確率は 30%。普通に考えて $\boldsymbol{x}$ は暖色ってことになるお。
やらない夫
では今度は、$f_{\boldsymbol{\theta}}(\boldsymbol{x}) = 0.2$ の時はどうだろう。
やる夫
暖色が 20% で、寒色が 80% だから $\boldsymbol{x}$ は寒色だお。
やらない夫
やる夫は今おそらく、$f_{\boldsymbol{\theta}}(\boldsymbol{x})$ の閾値を $0.5$ としてクラスを振り分けているはずだ。
\begin{eqnarray}
y =
\begin{cases}
1 & (f_{\boldsymbol{\theta}}(\boldsymbol{x}) \ge 0.5) \\[5pt]
0 & (f_{\boldsymbol{\theta}}(\boldsymbol{x}) < 0.5)
\end{cases}
\end{eqnarray}
やる夫
あぁ、別に意識はしてなかったけど、確かにそうだお。$f_{\boldsymbol{\theta}}(\boldsymbol{x}) \ge 0.5$ なら暖色だと思うし、逆は寒色だお。
やらない夫
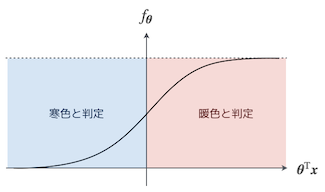
$f_{\boldsymbol{\theta}}(\boldsymbol{x}) \ge 0.5$ というのは、もっと詳しく見るとどういう状態だ?シグモイド関数のグラフを思い出して考えてみるんだ。
やる夫
んー…?シグモイド関数は $\boldsymbol{\theta}^{\mathrm{T}} \boldsymbol{x} = 0$ の時に $f_{\boldsymbol{\theta}}(\boldsymbol{x}) = 0.5$ だったお…あっ、要するに $f_{\boldsymbol{\theta}}(\boldsymbol{x}) \ge 0.5$ ってことは $\boldsymbol{\theta}^{\mathrm{T}} \boldsymbol{x} \ge 0$ ってことかお?
やらない夫
正解だ。さっきの場合分けの条件式の部分を書き直すとこうだな。
\begin{eqnarray}
y =
\begin{cases}
1 & (\boldsymbol{\theta}^{\mathrm{T}} \boldsymbol{x} \ge 0) \\[5pt]
0 & (\boldsymbol{\theta}^{\mathrm{T}} \boldsymbol{x} < 0)
\end{cases}
\end{eqnarray}
やらない夫
シグモイド関数のグラフをみると、こんな風に分類される感じだな。
やる夫
なるほど、わかりやすいお。でも、条件式の部分って $f_{\boldsymbol{\theta}}(\boldsymbol{x}) \ge 0.5$ でも $\boldsymbol{\theta}^{\mathrm{T}} \boldsymbol{x} \ge 0$ でも同じ意味ならなんでわざわざ書き直すんだお?
やらない夫
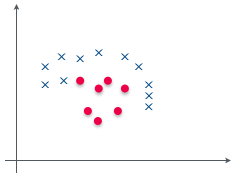
では、今度はパーセプトロンの時に見たような、横軸が赤($x_1$)、縦軸が青($x_2$) のグラフを考えてみようか。
やる夫
あぁ、色をプロットしていたアレかお。
やらない夫
今回の問題、素性としては赤 ($x_1$) と青 ($x_2$) の 2 次元だが、回帰の時と同じように $\theta_0$ と $x_0$ も含めて、全体としては 3 次元ベクトルで考えるぞ。いいか?
やる夫
大丈夫だお。$x_0 = 1$ は固定だったお。
やらない夫
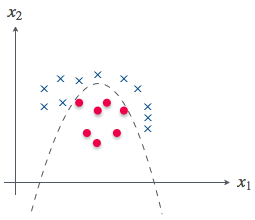
具体的に考えるために、適当にパラメータ $\boldsymbol{\theta}$ を決めよう。そうだな、こういう $\boldsymbol{\theta}$ があった時、暖色である場合の条件式 $\boldsymbol{\theta}^{\mathrm{T}} \boldsymbol{x} \ge 0$ をグラフに表すとどうなる?
$$
\boldsymbol{\theta} = \left[
\begin{array}{c}
\theta_0 \\ \theta_1 \\ \theta_2
\end{array}
\right] = \left[
\begin{array}{c}
-100 \\ 2 \\ 1
\end{array}
\right]
$$
やる夫
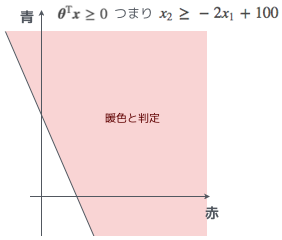
ん、条件式をグラフに…とりあえず $\boldsymbol{\theta}$ を代入して、わかりやすいように変形してみるお…
$$
\begin{eqnarray}
\boldsymbol{\theta}^{\mathrm{T}} \boldsymbol{x} = -100 + 2 x_1 + x_2 & \ge & 0 \
x_2 & \ge & - 2 x_1 + 100
\end{eqnarray}
$$
やる夫
これをグラフに…こうかお?
やらない夫
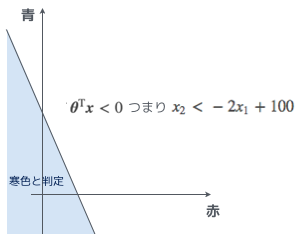
ここまでくれば $\boldsymbol{\theta}^{\mathrm{T}} \boldsymbol{x} < 0$ の場合がどうなるかも想像できるな?
やる夫
今度はさっきの反対側ってことかお。
やらない夫
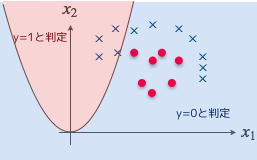
つまり $\boldsymbol{\theta}^{\mathrm{T}} \boldsymbol{x} = 0$ という直線を境界線として、一方が暖色($y=1$)、もう一方が寒色($y=0$)、とクラス分けできるというわけだ。
やる夫
これは直感的でわかりやすいお!パーセプトロンの時にも $\boldsymbol{w} \cdot \boldsymbol{x} = 0$ というクラスを分類するための線が出てきたけど、それと同じものってことかお。
やらない夫
そうだな。このようなクラスを分割する線を決定境界、英語では Decision Boundary と呼ぶ。
やる夫
この決定境界、暖色と寒色を分類する線としては全く正しくなさそうだけど、それはやらない夫が適当にパラメータの $\boldsymbol{\theta}$ を決めたから、ってことかお?
やらない夫
そういうことだ。ということは、これから何をやっていくのかは、想像つくだろう?
やる夫
正しいパラメータ $\boldsymbol{\theta}$ を求めるために、目的関数を定義して、微分して、パラメータの更新式を求める、であってるかお?
やらない夫
よくわかってるじゃないか。
尤度関数
やる夫
あとは回帰と同じなら楽勝だお。今日はもう帰ってオンラインゲームでもやるお。
やらない夫
そうだったら良かったんだが、世の中そんなに甘くないぞ。
やる夫
はっ…そういえば今日は週 1 のメンテナンス日だったお…
やらない夫
お前、そういうことじゃないだろ、常識的に考えて…。ロジスティック回帰は、二乗誤差の目的関数だとうまくいかないから別の目的関数を定義するんだ。最初にやった回帰と同じ手法ではやらない。
やる夫
そうなのかお…帰ってもやることないから、やらない夫の講義に付き合ってやるお。
やらない夫
その上から目線、癪に障るが…ロジスティック回帰の目的関数を考えよう。パーセプトロンの時に準備した学習用データについて、さっき俺が適当に決めたパラメータ $\boldsymbol{\theta}$ を使って、実際に $f_{\boldsymbol{\theta}}(\boldsymbol{x})$ を計算してみよう。ここで示す $f_{\boldsymbol{\theta}}(\boldsymbol{x})$ の計算結果は全く厳密ではないが、イメージをつかむにはそれで十分だろう。
| 色 |
クラス |
$y$ |
$f_{\boldsymbol{\theta}}(\boldsymbol{x})$ |
| #d80055 |
暖色 |
1 |
0.00005 |
| #c80027 |
暖色 |
1 |
0.00004 |
| #9c0019 |
暖色 |
1 |
0.00002 |
| #2c00c8 |
寒色 |
0 |
0.99991 |
| #120078 |
寒色 |
0 |
0.99971 |
| #40009f |
寒色 |
0 |
0.99953 |
やらない夫
$f_{\boldsymbol{\theta}}(\boldsymbol{x})$ は $\boldsymbol{x}$ が暖色である確率だと定義した。これは覚えているな。
やる夫
大丈夫だお。
やらない夫
では、それを踏まえた上で、$y$ と $f_{\boldsymbol{\theta}}(\boldsymbol{x})$ はどういう関係にあるのが理想的だと思う?
やる夫
えっ、えーっと… $f_{\boldsymbol{\theta}}(\boldsymbol{x})$ は $\boldsymbol{x}$ が暖色である確率なんだから…正しく分類されるためには、$y=1$ の時に $f_{\boldsymbol{\theta}}(\boldsymbol{x})$ が $1$ に近くて、$y=0$ の時に $f_{\boldsymbol{\theta}}(\boldsymbol{x})$ が $0$ に近い方がいい、ってことかお?
やらない夫
そうだな。理想の状態はやる夫の言った通りで正解だが、以下のようにも言い換えることができる。
- $y=1$ の時は $P(y=1|\boldsymbol{x})$ が最大になって欲しい
- $y=0$ の時は $P(y=0|\boldsymbol{x})$ が最大になって欲しい
やる夫
$P(y=1|\boldsymbol{x})$ は $\boldsymbol{x}$ が暖色である確率、逆に $P(y=0|\boldsymbol{x})$ が $\boldsymbol{x}$ が寒色である確率、という理解であってるかお?
やらない夫
それでいい。これを全ての学習用データについて考えるんだ。すると目的関数は以下のような同時確率として考えることができる。これを最大化する $\boldsymbol{\theta}$ を見つけることが目的だ。
$$
L(\boldsymbol{\theta}) = \prod_{i=1}^n P(y^{(i)}=1|\boldsymbol{x})^{y^{(i)}} P(y^{(i)}=0|\boldsymbol{x})^{1-y^{(i)}}
$$
やる夫
さて、帰るお。
やらない夫
期待通りの反応をありがとう。
やる夫
どうやったらこんな意味不明な式が思いつくんだお…。
やらない夫
確かに、式を簡潔にするために多少トリックを使ってはいるが、やる夫でも理解できるはずだ。1 つずつ考えよう。
やる夫
やらない夫の丁寧な説明をお待ちしておりますお。
やらない夫
$y^{(i)}$ が $1$ と $0$ の場合をそれぞれ考えてみよう。$y^{(i)}=1$ のデータの場合は後ろ側の $P(y^{(i)}=0|\boldsymbol{x})^{1-y^{(i)}}$ が $1$ になる。逆に $y^{(i)}=0$ のデータの場合は前の $P(y^{(i)}=1|\boldsymbol{x})^{y^{(i)}}$ が $1$ になる。
やる夫
ん、なんでだお?
やらない夫
両方とも 0 乗になるだろう。$P(y^{(i)}=1|\boldsymbol{x})$ や $P(y^{(i)}=0|\boldsymbol{x})$ がどんな数だったとしても、べき乗のところが 0 になるからだ。$P(y^{(i)}=1|\boldsymbol{x})^0$ も $P(y^{(i)}=0|\boldsymbol{x})^0$ も両方とも 0 乗なんだから、1 になるのは明確だ。
やる夫
あ、なるほど。確かに、言われてみればそうだお。
やらない夫
まとめるとこうだ。
- $y^{(i)}=1$ の時は $P(y^{(i)}=1|\boldsymbol{x})$ の項が残る
- $y^{(i)}=0$ の時は $P(y^{(i)}=0|\boldsymbol{x})$ の項が残る
やらない夫
つまり全ての学習用データにおいて、正解ラベルと同じラベルに分類される確率が最大になるような同時確率を考えているということだ。
やる夫
うーん、わかったようなわかってないような…前の回帰の時は目的関数の最小化だったけど、今回は最大化するのかお。
やらない夫
そうだな。二乗誤差はその名の通り “誤差” なので小さいほうが理想的だ。だが、今回は同時確率だ。その同時確率が最も高くなるようなパラメータ $\boldsymbol{\theta}$ こそ、学習用データにフィットしていると言える。そういった、尤もらしいパラメータを求めたいんだ。
やる夫
国語のお勉強も足りてないお…それなんて読むんだお。
やらない夫
“尤もらしい” は “もっともらしい” と読む。さっき定義した関数も、尤度関数とも呼ばれる。これは “ゆうどかんすう” だな。目的関数に使った文字 $L$ も、尤度を英語で表した時の $Likelihood$ の頭文字から取った。
やる夫
やっぱり、ここにきて難易度あがってるお。面倒くさいけど、あとで復習するお…
やらない夫
そうだな。どうせ家に帰ってやることがないんだろう。
やる夫
バカにするなお…
やる夫で学ぶ機械学習 - 対数尤度関数 - へ続く。