最近、畳み込みニューラルネットワークを使ったテキスト分類の実験をしていて、知見が溜まってきたのでそれについて何か記事を書こうと思っていた時に、こんな記事をみつけました。
http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp
畳み込みニューラルネットワークを自然言語処理に適用する話なのですが、この記事、個人的にわかりやすいなと思ったので、著者に許可をもらって日本語に翻訳しました。なお、この記事を読むにあたっては、ニューラルネットワークに関する基礎知識程度は必要かと思われます。
※日本語としてよりわかりやすく自然になるように、原文を直訳していない箇所もいくつかありますのでご了承ください。翻訳の致命的なミスなどありましたら、Twitterなどで指摘いただければすみやかに修正します。
以下訳文
畳み込みニューラルネットワーク (CNN) という言葉を聞いた時、普通はコンピュータービジョンのことを思い浮かべるでしょう。CNN は過去に画像分類の分野においてブレークスルーを引き起こし、今日では Facebook の写真の自動タギングから自動運転車に至るまで、ほとんどのコンピュータービジョンシステムの中核となっています。
そして近年、自然言語処理 (NLP) の領域の問題に対しても CNN が適用されはじめ、いくつか興味深い結果を得ています。この記事では CNN とはいったい何なのかということ、またどのようにして NLP の領域で使われるのか、ということを説明してみたいと思います。コンピュータービジョンでのユースケースを話した方が CNN においてはいくぶん直感的ですので、まずはそこから始めたいと思います。そしてゆっくりと NLP の話題へ移っていきましょう。
畳み込みとは?
私は、畳み込みについては、行列に適用されるスライド窓関数 (sliding window function) として考えるとわかりやすいと思います。言葉でこう書くとちょっと難しいかもしれませんが、視覚的に表してみると非常にわかりやすいです。
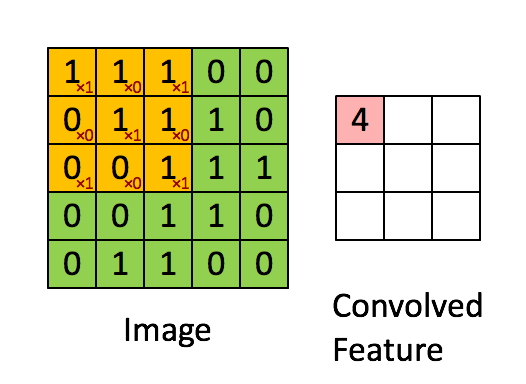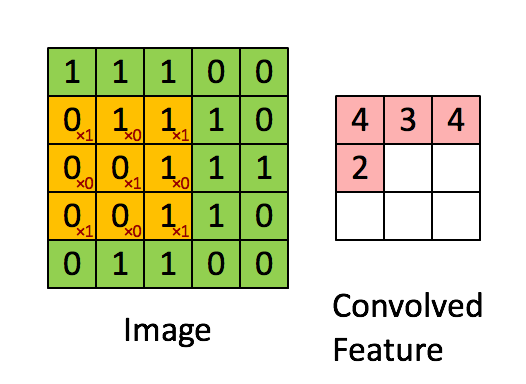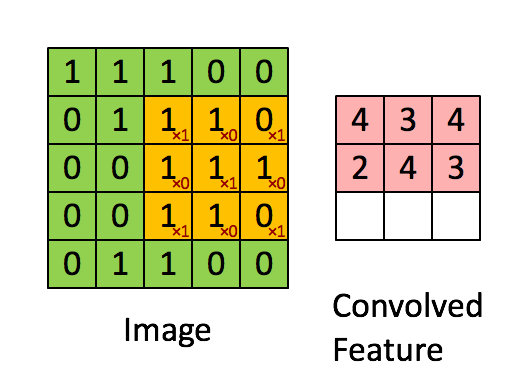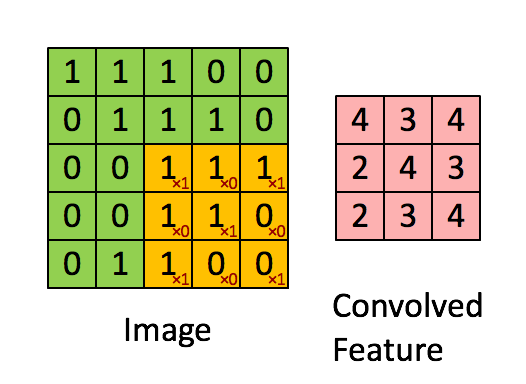
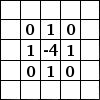
3x3 の畳み込みフィルタ。引用元:
http://deeplearning.stanford.edu/wiki/index.php/Feature_extraction_using_convolution
左側にある行列は白黒の画像を表していると考えてください。行列の各要素はそれぞれ画像の 1 つのピクセルに対応しており、0 が黒、1 が白です (一般的には 0 から 255 の間の値を取るグレースケールの画像)。スライド窓はカーネル (kernel) やフィルタ (filter) または特徴検出器 (feature detector) などと呼ばれます。ここでは 3x3 のフィルタを使っており、そのフィルタの値と行列の値を要素毎に掛けあわせ、それらの値を合計します。この操作を、行列全体をカバーするようにフィルタをスライドさせながら各要素に対して行っていき、全体の畳み込みを取得します。
でも結局これで何が出来るの?と不思議に思いませんか。ここで直感的な例を挙げてみましょう。
各ピクセルとその周囲を平均して画像をぼかす:


各ピクセルとその周囲の差分をとってエッジを検出する:
(これを直感的に理解するためには、ピクセルの色が周囲の色と同じであるような色の変化がなめらかな部分で、どういうことが起こるのかを考えてみましょう。そういった部分にこのフィルタを適用すると、可算が相殺されて結果的には 0、つまり黒になります。逆に、明度が極端に違うエッジの部分であれば - これはたとえば白から黒へ移り変わっている部分 - においては、差分が大きくなり結果的には白くなります。)

GIMP のマニュアル には、ここで紹介した以外のサンプルがいくつか含まれています。畳み込みについてより詳しく理解したければ Chris Olah の記事 も読んでみることをオススメします。
畳み込みニューラルネットワークとは?
さて、これで畳み込みの正体はわかりました。しかし、CNN とは一体なんでしょう?CNN は、ReLU や tanh のような非線形な活性化関数を通した、いくつかの畳み込みの層のことです。伝統的な順伝搬型ニューラルネットワークでは、それぞれの入力ニューロンは次の層のニューロンにそれぞれ接続されており、これは全結合層やアフィン層とも呼ばれます。しかし CNN ではそのようなことはせずに、ニューロンの出力を計算するのに畳み込みを使います。これによって、入力となるニューロンのある領域が、それぞれ対応する出力のニューロンに接続されているような、局所的な接続ができることになります。各層は別々の異なるフィルタを適用し - これは一般的には 100 〜 1000 程度の数になりますが - それらを結合します。これをプーリング層 (subsampling) と呼びます。これについては後ほど詳しくお話します。CNN の学習フェーズでは、解決したいタスクに適応できるように フィルタの値を自動的に学習していきます。たとえば画像分類の話でいうと、CNN は最初の層で生のピクセルデータからエッジを検出するための学習を進め、そのエッジを使って今度は次の層で単純な形状を検出し、さらにより深い層ではその形状を使ってより高レベルな特徴、つまり顔の形状などの特徴を検出するようになります。そして最後の層は、そういった高レベルな特徴を使った分類器となります。
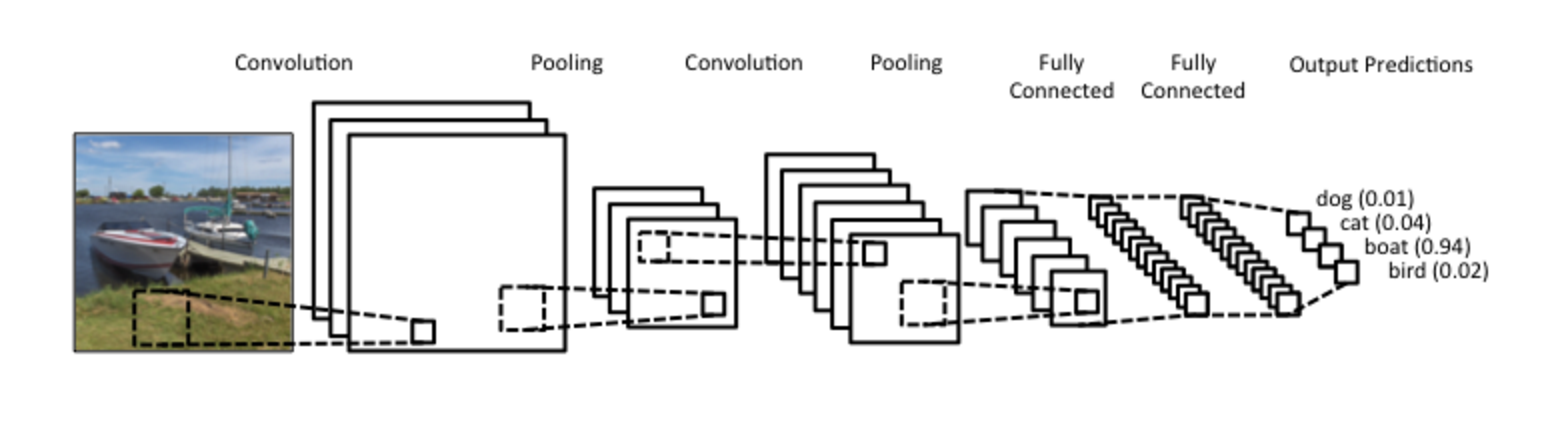
さて、畳み込み計算には注目に値すべき点が 2 つあります。位置不変性 (Location Invariance) と 構成性 (Compositionality) です。画像の中に象が写っているかどうかを判別したいとしましょう。畳み込み層では画像全体にわたってフィルタをスライドさせていくので、画像中のどこに象が現れるのかを気にしなくてもよいのです。またプーリング層でも、平行移動、回転、スケーリングに対して不変性を得ることができますが、これは後述します。そしてもう 1 つの鍵は構成性です。各フィルタは、低レベルな特徴である画像の一区画から、より高レベルな特徴を表現できるようにしてくれます。これがコンピュータービジョンにおいて CNN が非常に強力である理由です。ピクセルからエッジを、エッジから形状を、そしてその形状からより複雑なオブジェクトを構築する、という流れは直感的に理にかなっています。
これらをどうやって NLP へ適用するのか?
画像分類では入力は画像のピクセル列になりますが、ほとんどの NLP タスクではピクセル列の代わりに、行列で表現された文章または文書が入力となります。行列の各行は 1 つのトークンに対応しており、一般的には単語がトークンになることが多いですが、文字がトークンでもかまいません。すなわち、各行は単語を表現するベクトルです。普通、これらのベクトルは word2vec や GloVe のような低次元な単語埋め込み表現 (word embeddings) を使いますが、one-hot ベクトルでもかまいません。100 次元の単語埋め込みを使った 10 単語の文章があった場合、10x100 の行列となります。これが NLP における “画像” です。
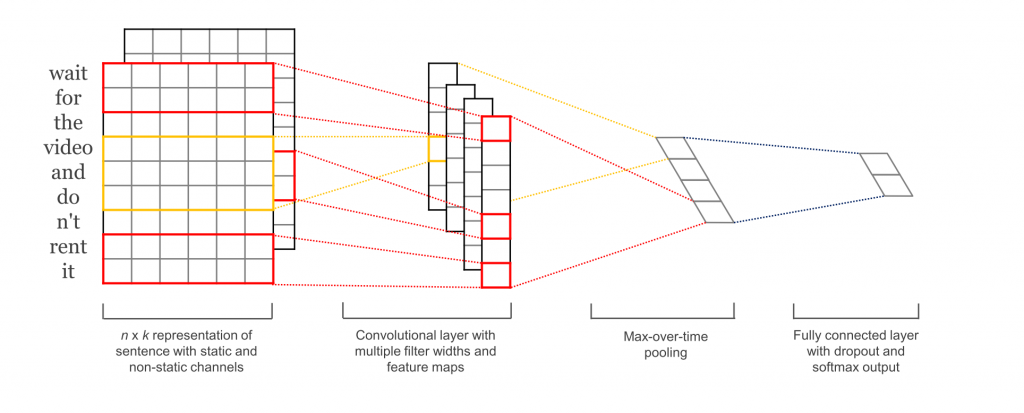
コンピュータービジョンでは、フィルタは画像のある区画上をスライドしていきますが、NLP では一般的に行列の行全体 (つまり単語毎) をスライドするフィルタを使います。つまり、フィルタの幅は入力となる行列の幅と同じにします。高さは様々ですが、一般的には 2-5 くらいの単語くらいでしょうか。これらのことを加味すると NLP の畳み込みニューラルネットワークはこんな感じになります (少し時間をかけてこの図を見て、どんな風に計算されていくのかを理解してみてください。プーリングについては今のところは無視してください、後でちゃんと説明します)。
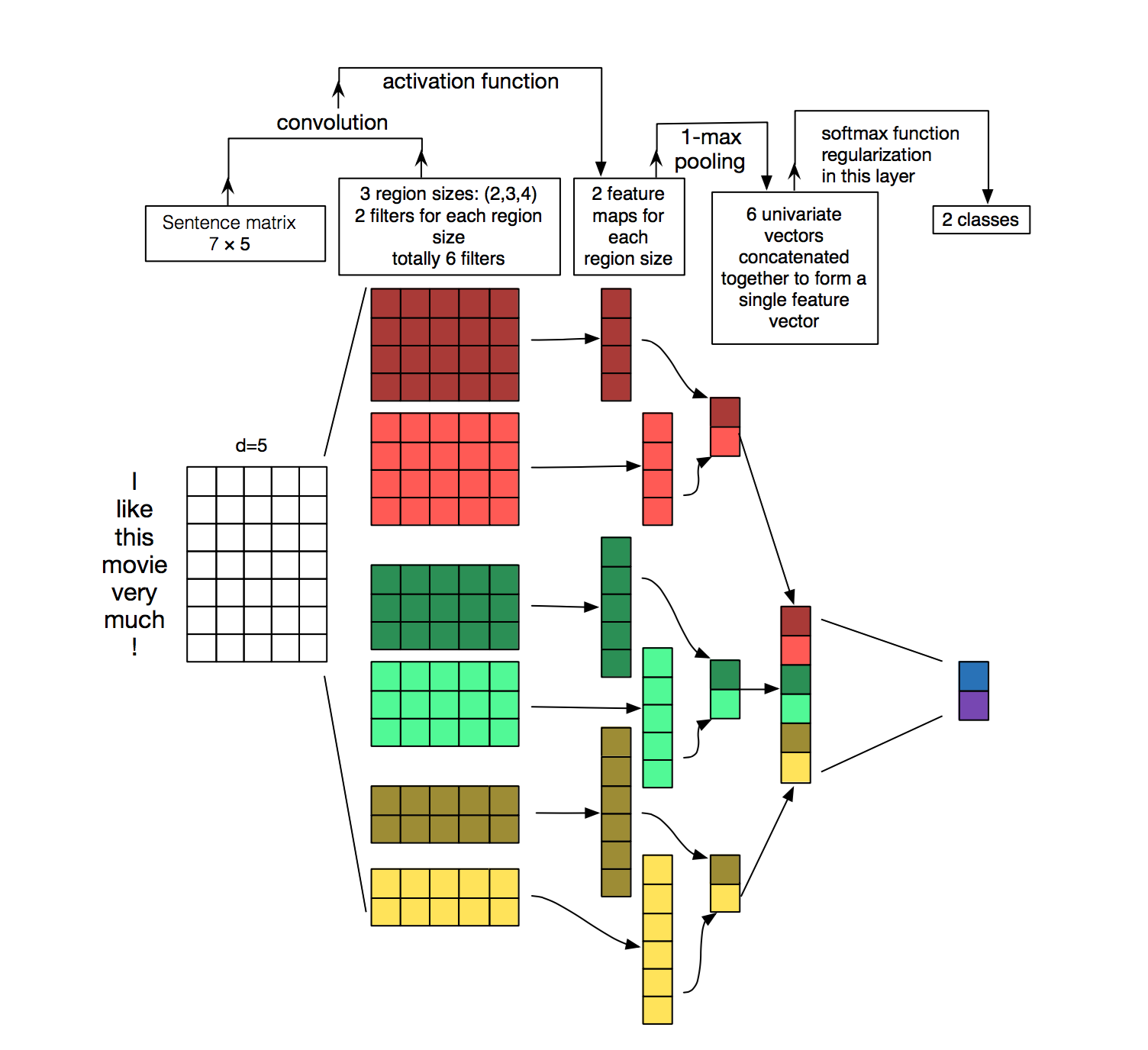
文章分類のための畳み込みニューラルネットワーク (CNN) のアーキテクチャを説明した図。この図には 2、3、4 の高さをもったフィルタが、それぞれ 2 つずつあります。各フィルタは文章の行列上で畳み込みを行い、特徴マップを生成します。それから、各特徴マップに対して最大プーリングをかけていき、各特徴マップの中で一番大きい値を記録していきます。そして、全 6 つの特徴マップから単変量な特徴 (univariate feature) が生成され、それら 6 つの特徴は結合されて、それが最後から 2 番目の層になります。一番最後の softmax 層では先程の特徴を入力として受け取り、文章を分類します。ここでは二値分類を前提としていますので、最終的には 2 つの出力があります。
引用元: hang, Y., & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification
位置不変性と構成性は、画像においては直感的にわかりますが、NLP の場合はそうではありません。NLP ではたぶん、文章内で単語が出現する場所なんかを気にするんじゃないでしょうか。お互いに近くにあるピクセル同士は意味的に関連している、つまりは同じオブジェクトであると言えると思いますが、単語においてそれは常にそうとは限りません。多くの言語において、フレーズの一部は単語によって区切ることができます。こういった文章の組成は明確なものではありません。単語のより高レベルな表現 (たとえば実際の単語の “意味” など) はピュータービジョンほど明らかではなく、一体この NLP に対する CNN はどうやって動作しているのでしょうか。
こうなると、CNN は NLP のタスクにはうまく適合しないんじゃないかという気がしてきます。リカレントニューラルネットワーク はもっと直感的ですし、実際に人間が言語を処理するやり方に似ています。左から右に順番に読んでいく方法ですね。とは言っても、これまでの説明は決して CNN がうまく動かないという意味ではありません。完璧なモデルなど無いが、それでも役に立つモデルはある という言葉がありますが、NLP の問題へ適用された CNN は、結果的にはとてもよい性能を発揮します。単純な Bag of Words モデル は誤った仮定のもと単純化しすぎなのは明らかですが、にもかかわらずしばらくは一般的なアプローチであり、人々はそれを使ってより良い結果を得ようとしてきました。
CNN を使う言い分としては、とても速いということです。非常に速いです。畳み込みはコンピューターグラフィックスにおいて重要なものであり GPU 上にハードウェアレベルで実装されています。n-grams のようなものと比べて CNN は効率的に単語を表現ができます。ボキャブラリーが巨大な場合、3-grams 以上のものは計算量が多すぎてすぐに計算できなくなります。Google でさえ 5-grams を超えるものは提供していません。畳み込みフィルタはボキャブラリー全体を表現する必要なく、勝手に適切な表現を学習してくれます。最初の層にあるたくさんの学習済みのフィルタは n-grams と非常に良く似た特徴を捉えますが、よりコンパクトな表現を得ることができると考えると良いでしょう (しかも計算量が多すぎて計算ができないといった制限もありません)。
CNN のハイパーパラメータ
CNN を NLP へ適用するやり方を説明する前に、CNN を構築する際に必要となってくるものがいくつかありますのでそれを見ていきましょう。きっと CNN 理解の手助けとなるはずです。
畳み込み幅のサイズ
私が最初に畳み込みの説明をした時、フィルタを適用する際の詳細について説明を飛ばしたものがあります。行列の真ん中辺りに 3x3 のフィルタを適用するのは問題ありませんが、それではフチの辺りに適用する場合はどうでしょうか?行列の左側にも上側にも隣接した要素がないような、たとえば行列の最初の要素にはどうやってフィルタを適用すればよいでしょうか?そういった場合には、ゼロパディングが使えます。行列の外側にはみ出してしまう要素は全て 0 で埋めるのです。こうすることで、入力となる行列の全要素にわたってフィルタを適用することができます。ゼロパディングを行うことは wide convolution とも呼ばれ、逆にゼロパディングをしない場合は narrow convolution と呼ばれます。1 次元での例を見てみましょう。
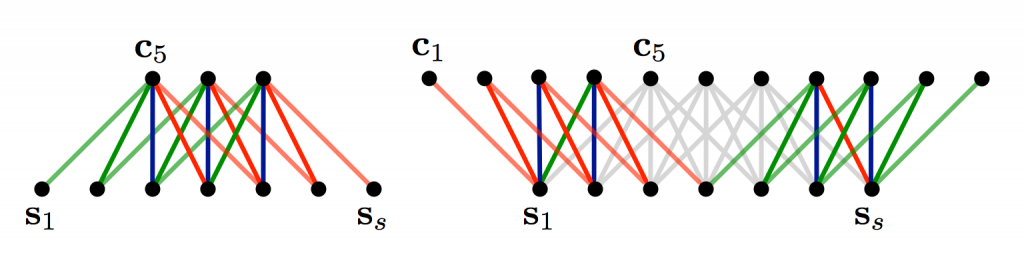
Narrow Convolution と Wid Convolution。フィルタのサイズは 5 で、入力データのサイズは 7。引用元: A Convolutional Neural Network for Modelling Sentences (2014)
入力データのサイズに対してフィルタサイズが大きい時には wide convolution が有用です。narrow convolution は出力されるサイズが $(7 - 5) + 1 = 3$ になりますし、wide convolutin は $(7 + 2 * 4 - 5) + 1 = 11$ になります。一般化すると、出力サイズは $n_{out}=(n_{in} + 2*n_{padding} - n_{filter}) + 1$ です。
ストライド
ストライドという畳み込みのもう一つのハイパーパラメータがあります。これはフィルタを順に適用していく際に、フィルタをどれくらいシフトするのかという値です。これまでに示してきた例は全てストライド 1 で、フィルタは重複しながら連続的に適用されています。ストライドを大きくするとフィルタの適用回数は少なくなって、出力のサイズも小さくなります。以下のような図が Stanford cs231 にありますが、これは 1 次元の入力に対して、ストライドのサイズが 1 または 2 のフィルタを適用している様子です。
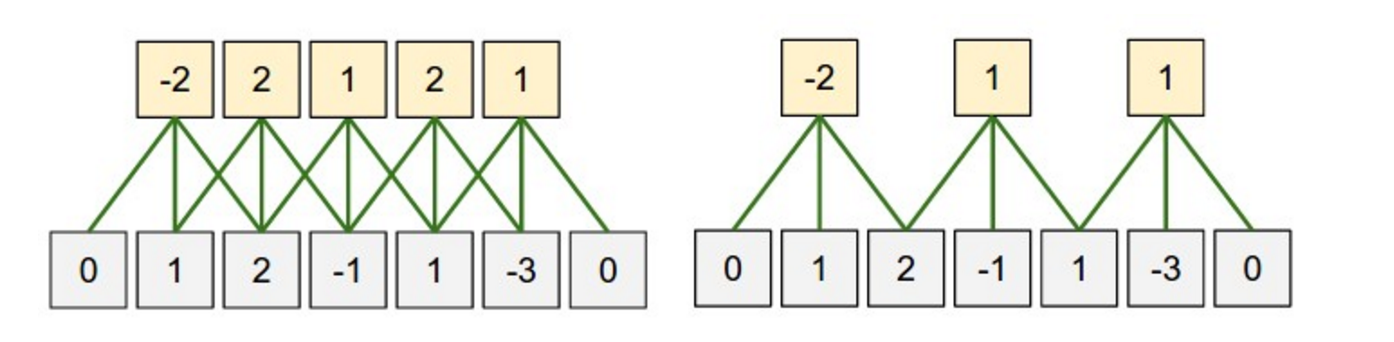
畳み込みのストライドのサイズ。左側のストライドは 1。右側のストライドは 2。引用元: http://cs231n.github.io/convolutional-networks/
普通、文書においてはストライドのサイズは 1 ですが、ストライドのサイズを大きくすることで、例えばツリーのような 再帰型ニューラルネットワーク と似た挙動を示すモデルを作れるかもしれません。
プーリング層
畳み込みニューラルネットワークの鍵は、畳み込み層の後に適用されるプーリング層です。プーリング層は、入力をサブサンプリングします。最も良く使われるプーリングは、各フィルタの結果の中から最大値を得る操作です。ただ、畳み込み結果の行列全体にわたってプーリングする必要はなく、指定サイズのウィンドウ上でプーリングすることもできます。たとえば、以下の図は 2x2 のサイズのウィンドウ上で最大プーリングを実行した様子です (NLP では一般的に出力全体にわたってプーリングを適用します。つまり各フィルタからは 1 つの数値が出力されることになります)。
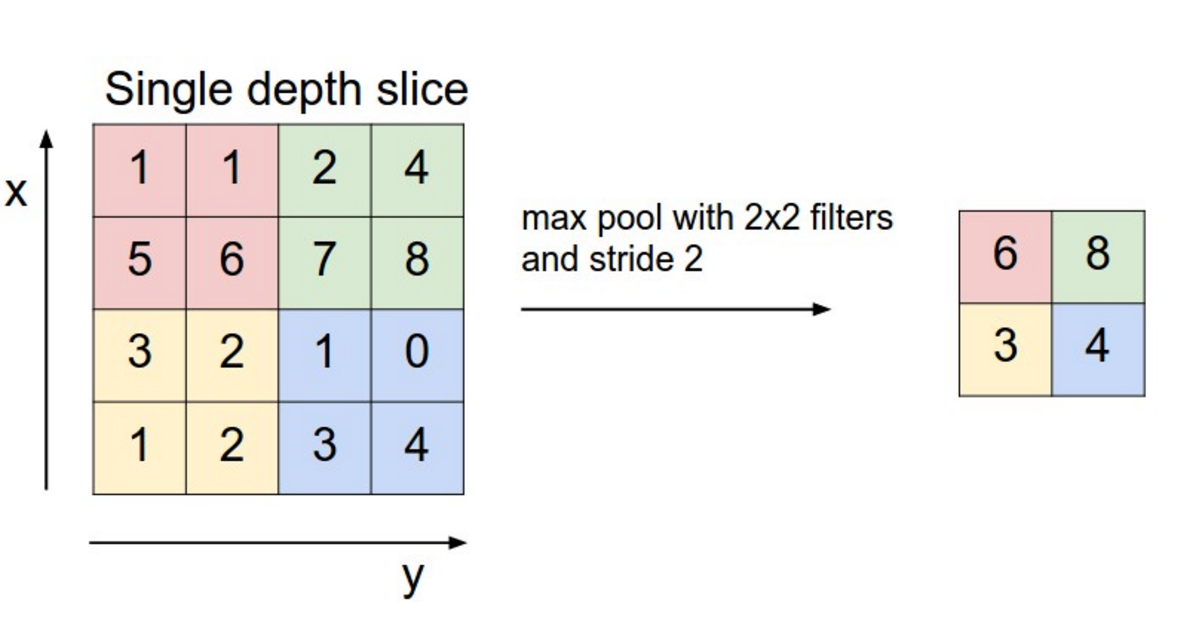
CNN における最大プーリング。引用元: http://cs231n.github.io/convolutional-networks/#pool
プーリング層をはさむ理由はいくつかあります。プーリングの特徴の 1 つは、出力される行列が固定サイズになるということです。たとえば 1000 個のフィルタがあってそれぞれのフィルタに対して最大プーリングを適用したとすると、入力のサイズやフィルタのサイズがどんなものであっても結果としては 1000 次元の出力が得られますね。これはつまり、文章のサイズやフィルタのサイズが可変だったとしても、最終的に分類器へデータが渡ってくる時点では常に同じ次元になっているということです。
また、プーリングは次元削減も行いますが、単に次元を削減するのではなく必要な情報は維持したまま次元を削減してくれます。フィルタをある特定の特徴を抽出するためのものとして考えるのです。たとえば “not amazing” などの否定が文章内に含まれているかどうかを検出するためのもの、という感じです。もしこんなフレーズが文章のどこかにでてきた場合、その部分にフィルタを適用すると、出力される計算結果は大きな値になるでしょう。しかし、それ以外の別の部分にフィルタを適用した場合は、出力結果は小さな値になるでしょう。最大プーリングを適用することで、文章中に “とある特徴” が存在するかどうかという情報は残ったままですが、その特徴が実際にどこに出現するのかといった情報は失われることになります。しかし、このような位置に関する情報は本当に消えても大丈夫なのでしょうか?答えは yes です。n-grams モデルも似たようなものです。位置に関する情報は失いますが、フィルタによって捉えられた局所的な情報 - たとえば “not amazing” と “amazing not” の違いなど - は残ったままなのです。
画像認識での話ですが、プーリングは位置と回転に不変性を与えます。ある領域についてプーリングを行うと、画像が数ピクセルだけ移動や回転をしてもその出力はほぼ同じになります。それは最大プーリングが、微妙なピクセルの違いを無視して同じ値を抽出してきてくれるからです。
チャンネル
最後はチャンネルです。チャンネルとは、入力データを異なる視点から見たものと言えるでしょう。画像認識での例を挙げると、普通は画像は RGB (red, green, blue) の 3 チャンネルを持っています。畳み込みはこれらのチャンネル全体に適用でき、その時のフィルタは各チャンネル毎に別々に用意してもいいですし、同じものを使ってもかまいません。NLP では、異なる単語埋め込み表現 (word2vec や GloVe など) でチャンネルを分けたり、同じ文章を異なる言語で表現してみたり、また異なるフレーズで表現してみたり、という風にして複数チャンネルを持たせることができそうですね。
NLP へ適用された畳み込みニューラルネットワーク
それでは、自然言語処理に対して CNN を使ったアプリケーションの研究結果について見ていきましょう。CNN のアプリケーションについては私が知らないものもたくさんありますが、少なくとも有名な研究結果についてはカバーできていると思います。
CNN が得意なのは、感情分析 (Sentiment Analysis) やスパム検出 (Spam Detection)、カテゴリ分類 (Topic Categorization) などの分類問題です。畳み込みとプーリングの操作を適用すると、単語の局所的な位置情報は失われますので、品詞タグ付け (PoS Tagging) や固有表現抽出 (Entity Extraction) などを目的として、純粋な CNN を使うのはちょっと難しいでしょう (ただ、入力データに位置情報に関する特徴を追加すれば不可能ではないと思います)。
[1] では、主に感情分析とカテゴリ分類から成る様々なデータセット上で CNN のアーキテクチャを評価しています。CNN は全体的にとても良いパフォーマンスを発揮しています。この論文で使われているネットワークは非常にシンプルなのに、とても強力なので驚きです。入力層は word2vec による単語埋め込み表現で構成された文章で、その後に複数のフィルタを持つ畳み込み層と最大プーリング層が続き、そして最後に softmax 分類器があります。この論文では、一方は学習中に微修正されていく動的な単語埋め込み表現、もう一方は学習中に変化しない静的な単語埋め込み表現、といった 2 つの異なるチャンネルを持つデータに対する実験もしています。似てはいますが、もう少し複雑なアーキテクチャが [2] で提案されています。[6] では “semantic clustering” と呼ばれる操作を行う層をネットワークに追加しています。
Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification
[4] では、word2vec や GloVe などを使った単語ベクトルの事前学習はせずに、one-hot なベクトルに対して直接畳み込みを適用して、スクラッチで CNN を学習させています。著者はまた、空間効率の良い (space-efficient) BoW のような表現を提案しており、ネットワークが学習するパラメータ数を減らしています。[5] では、CNN を使ってテキストのある領域のコンテキストを予測する “region embedding” と呼ばれる教師なしのモデルを拡張しています。これらの論文のアプローチは長いテキスト (たとえば映画のレビューのような) に対してはうまく動作しているように見えますが、短いテキスト (ツイートなど) に対してはそうではありません。短いテキストに対しては、単語埋め込み表現を事前学習しておいた方がより良い結果になりそうですね。
CNN を実装するためには、いろいろなハイパーパラメータを決める必要があります。いくつかは先ほど紹介しましたが、入力データのベクトル表現 (word2vec なのか GloVe なのか one-hot なのか)、その数、畳み込みフィルタのサイズ、プーリングの方法 (最大プーリングなのか平均プーリングなのか)、活性化関数 (ReLU なのか tanh なのか)、などです。[7] では CNN のハイパーパラメータを様々に変化させながら、その時の CNN のパフォーマンスと複数回実行した際の分散を調査し、評価しています。もし、あなたが自分でテキスト分類問題を解くための CNN を実装するつもりであれば、この論文の結果を初期値として使うのが良いでしょう。この論文によると、平均プーリングより最大プーリングの方が毎回いい結果を出しており、理想的なフィルタサイズを考えるのはとても重要ですがそれはタスク毎に異なっています。それから、正則化項を導入しても NLP においては結果が大きく変わることはないようです。1 つ注意点としては、この研究で使っているデータセットはどれもテキストの長さが非常に似ているものばかりですので、テキスト長が明らかに異なるようなデータに対しては同じように考えることは恐らくできないでしょう。
[8] では関係抽出 (Relation Extraction) と関係分類 (Relation Classification) に対して CNN の研究をしています。単語ベクトルに関して、興味のあるエンティティに対する単語の相対位置を畳み込み層への入力として使っています。このモデルは、エンティティの位置はあらかじめ与えられているものとして、各サンプルデータはそれぞれ 1 つの関連を含んでいます。[9] と [10] でも似たようなモデルを使っています。
他の面白そうなユースケースとしては Microsoft Research から発表された [11] と [12] があります。これらの論文は、情報検索システムで使われる文章の “意味に関する有用な表現” をどうやって学習するのかを説明しています。ユーザーが現在読んでいるテキストをベースとして、ユーザーが潜在的に興味があるであろう文書をオススメする手法が例として含まれています。この文書表現は検索エンジンのログデータを元に学習されます。
ほとんどの CNN アーキテクチャは、学習プロセスの一部として単語及び文章に対しての埋め込み表現 (より低次元な表現) を学習します。すべての論文がこのやり方に沿っているわけではありませんし、有用な埋め込み表現をどのように学習するのかという調査をしているわけでもありません。[13] では、単語や文章に対する埋め込み表現を生成しながら Facebook への投稿のハッシュタグを予測する CNN を紹介しています。こういった学習済みの埋め込み表現は、他のタスクに適用してもうまくいきます。
キャラクターレベル CNN
ここまでは、どのモデルも単語をベースにしたものでした。しかし文字に対して直接 CNN を適用する研究も続けられてきました。[14] では文字レベル (character-level) で埋め込み表現を学習し、それらを事前学習した単語埋め込み表現と結合し、品詞タグ付けをするために CNN を使っています。[15] と [16] では、事前学習された埋め込み表現を使わずに、文字から直接学習する CNN を説明しています。とりわけ著者は、全部で 9 個の層を持つ比較的深いネットワークを感情分析やテキスト分類に適用しています。大規模なデータセット (100万件程度のデータ) を使えば、文字レベルの入力を直接学習することで良い結果が得られることがわかっていますが、小規模なデータセット (数千件程度のデータ) しかない場合は単純なモデルにも負けてしまいます。[17] では文字レベルの CNN の出力を LSTM への入力として使うようなアプリケーションに対する説明をしています。これは様々な言語に適用できます。
驚くべきは、これらの論文は全て過去 1-2 年の間で公開された論文だということです。NLP に CNN を適用する以前から、自然言語処理界隈では CNN を使わずに スクラッチで 素晴らしい成果を出してきましたが、最近の新しい結果や最新のシステムが公開されるスピードは加速し続けていますね。
参考論文
- [1] Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), 1746–1751.
- [2] Kalchbrenner, N., Grefenstette, E., & Blunsom, P. (2014). A Convolutional Neural Network for Modelling Sentences. Acl, 655–665.
- [3] Santos, C. N. dos, & Gatti, M. (2014). Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts. In COLING-2014 (pp. 69–78).
- [4] Johnson, R., & Zhang, T. (2015). Effective Use of Word Order for Text Categorization with Convolutional Neural Networks. To Appear: NAACL-2015, (2011).
- [5] Johnson, R., & Zhang, T. (2015). Semi-supervised Convolutional Neural Networks for Text Categorization via Region Embedding.
- [6] Wang, P., Xu, J., Xu, B., Liu, C., Zhang, H., Wang, F., & Hao, H. (2015). Semantic Clustering and Convolutional Neural Network for Short Text Categorization. Proceedings ACL 2015, 352–357.
- [7] Zhang, Y., & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification,
- [8] Nguyen, T. H., & Grishman, R. (2015). Relation Extraction: Perspective from Convolutional Neural Networks. Workshop on Vector Modeling for NLP, 39–48.
- [9] Sun, Y., Lin, L., Tang, D., Yang, N., Ji, Z., & Wang, X. (2015). Modeling Mention , Context and Entity with Neural Networks for Entity Disambiguation, (Ijcai), 1333–1339.
- [10] Zeng, D., Liu, K., Lai, S., Zhou, G., & Zhao, J. (2014). Relation Classification via Convolutional Deep Neural Network. Coling, (2011), 2335–2344.
- [11] Gao, J., Pantel, P., Gamon, M., He, X., & Deng, L. (2014). Modeling Interestingness with Deep Neural Networks.
- [12] Shen, Y., He, X., Gao, J., Deng, L., & Mesnil, G. (2014). A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval. Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management – CIKM ’14, 101–110.
- [13] Weston, J., & Adams, K. (2014). # T AG S PACE : Semantic Embeddings from Hashtags, 1822–1827.
- [14] Santos, C., & Zadrozny, B. (2014). Learning Character-level Representations for Part-of-Speech Tagging. Proceedings of the 31st International Conference on Machine Learning, ICML-14(2011), 1818–1826.
- [15] Zhang, X., Zhao, J., & LeCun, Y. (2015). Character-level Convolutional Networks for Text Classification, 1–9.
- [16] Zhang, X., & LeCun, Y. (2015). Text Understanding from Scratch. arXiv E-Prints, 3, 011102.
- [17] Kim, Y., Jernite, Y., Sontag, D., & Rush, A. M. (2015). Character-Aware Neural Language Models.